Model Market
Where the AI model market stands this week — frontier, value, and the story behind the numbers.
As of June 7, 2026 · refreshed weekly from Artificial Analysis snapshots · methodology and sourcing in the footer below
354
priced LLMs tracked
11
on the frontier
3.1%
survive the price test
33
creators represented
Of 354 priced LLMs in this snapshot, only 11 — about 3% — sit on the intelligence-price frontier: no cheaper model matches their intelligence, and nothing smarter costs less. That thin set is the actual shortlist once price enters the room; the other 97% are dominated, whatever the leaderboard says.
The intelligence-price frontier
A model is on the frontier when no cheaper model matches its intelligence index, and nothing smarter costs less. This is the set that survives a basic economic sanity check — not "the best," but the rational choices at each price point.
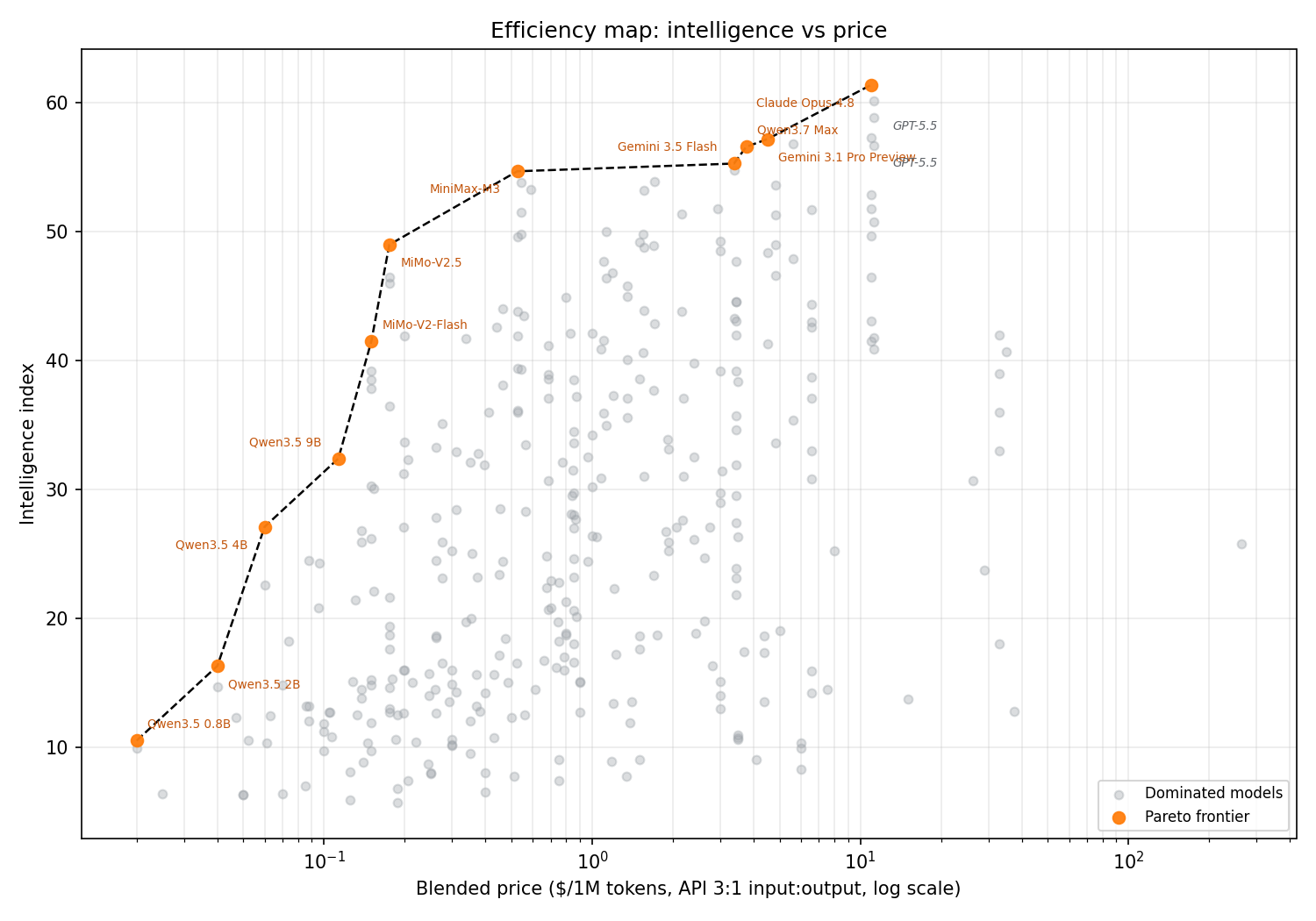
| # | Model | Creator | Intelligence | Price ($/M tok) | Index per $ | Output tok/s |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.8 (Adaptive Reasoning, Max Effort) | Anthropic | 61.4 | $10.94 | 5.6 | 69 |
| 2 | Gemini 3.1 Pro Preview | 57.2 | $4.50 | 12.7 | 137 | |
| 3 | Qwen3.7 Max | Alibaba | 56.6 | $3.75 | 15.1 | 105 |
| 4 | Gemini 3.5 Flash (high) | 55.3 | $3.38 | 16.4 | 226 | |
| 5 | MiniMax-M3 | MiniMax | 54.7 | $0.525 | 104.2 | 46 |
| 6 | MiMo-V2.5 | Xiaomi | 49.0 | $0.175 | 280.0 | 82 |
| 7 | MiMo-V2-Flash (Feb 2026) | Xiaomi | 41.5 | $0.150 | 276.7 | 119 |
| 8 | Qwen3.5 9B (Reasoning) | Alibaba | 32.4 | $0.113 | 286.7 | 82 |
| 9 | Qwen3.5 4B (Reasoning) | Alibaba | 27.1 | $0.060 | 451.7 | 207 |
| 10 | Qwen3.5 2B (Reasoning) | Alibaba | 16.3 | $0.040 | 407.5 | — |
| 11 | Qwen3.5 0.8B (Reasoning) | Alibaba | 10.5 | $0.020 | 525.0 | — |
Best model for the job
The composite intelligence index is one sort order among several. Sorting the same catalog by coding, math, value, or speed surfaces a different shortlist each time — proof that "best" depends on the job, not the leaderboard.
Intelligence
- 1. Claude Opus 4.8 (Adaptive Reasoning, Max Effort) 61.4
- 2. GPT-5.5 (xhigh) 60.2
- 3. GPT-5.5 (high) 58.9
Coding
- 1. GPT-5.5 (xhigh) 59.1
- 2. GPT-5.5 (high) 58.5
- 3. GPT-5.4 (xhigh) 57.2
Math
- 1. GPT-5.2 (xhigh) 99.0
- 2. GPT-5 Codex (high) 98.7
- 3. Gemini 3 Flash Preview (Reasoning) 97.0
Value (index per $)
- 1. Qwen3.5 0.8B (Reasoning) 525.0
- 2. Qwen3.5 0.8B (Non-reasoning) 495.0
- 3. Qwen3.5 4B (Reasoning) 451.7
Speed (output tok/s)
- 1. Mercury 2 1075
- 2. Granite 4.0 H Small 495
- 3. gpt-oss-120b (low) 373
Sort the same catalog by five different jobs and the leaderboard rearranges completely. OpenAI's GPT-5.5 variants and Anthropic's Claude Opus 4.8 own the top of intelligence and coding — but neither appears on the value or speed lists, which belong to Alibaba's smallest Qwen models and niche speed specialists like Mercury 2 and IBM's Granite line. There is no single 'best' model on this catalog; there's only the axis that matches the job in front of you.
Beyond text
The frontier above is an LLM story — intelligence and price for text generation. Image, video, and speech models are a separate market with their own leaderboards, ranked here by human-preference Elo (Artificial Analysis's blind side-by-side battles) rather than benchmark scores, since "best" in a generated image or video is a matter of taste.
Text to image
- 1. GPT Image 2 (high) — OpenAI 1339
- 2. GPT Image 1.5 (high) — OpenAI 1266
- 3. Nano Banana 2 (Gemini 3.1 Flash Image Preview) — Google 1260
Image editing
- 1. Riverflow 2.0 — Sourceful 1293
- 2. GPT Image 1.5 (high) — OpenAI 1265
- 3. GPT Image 2 (high) — OpenAI 1259
Text to speech
- 1. Fun-Realtime-TTS — Alibaba 1231
- 2. Gemini 3.1 Flash TTS — Google 1229
- 3. xAI Text to Speech — xAI 1208
Text to video
- 1. HappyHorse-1.0 — Alibaba-ATH 1293
- 2. Dreamina Seedance 2.0 720p — ByteDance Seed 1274
- 3. Kling 3.0 1080p (Pro) — KlingAI 1251
Image to video
- 1. Dreamina Seedance 2.0 720p — ByteDance Seed 1343
- 2. grok-imagine-video — xAI 1327
- 3. grok-imagine-video-1.5-preview — xAI 1325
Step outside text generation and almost none of the names above carry over. OpenAI's GPT Image models top both image generation and editing — the one carryover from the LLM world — but Sourceful's Riverflow 2.0 nearly outranks them on editing, and nothing from Anthropic, Google's flagship line, or Alibaba's Qwen cracks the leaderboard at all. Video belongs to an entirely different cast: Alibaba-ATH, ByteDance Seed, KlingAI, and xAI's Grok Imagine models, ranked here by human-preference Elo rather than benchmark scores, since 'best' in image and video is a matter of taste, not a test score. The intelligence-price frontier and the creative leaderboard are, in effect, two separate markets with two separate sets of winners.
The frontier is moving
Tracking the same intelligence-price plane across 4 weekly snapshots since 2026-05-25 — who enters and exits the frontier, and whether it's getting more or less expensive to be on it.
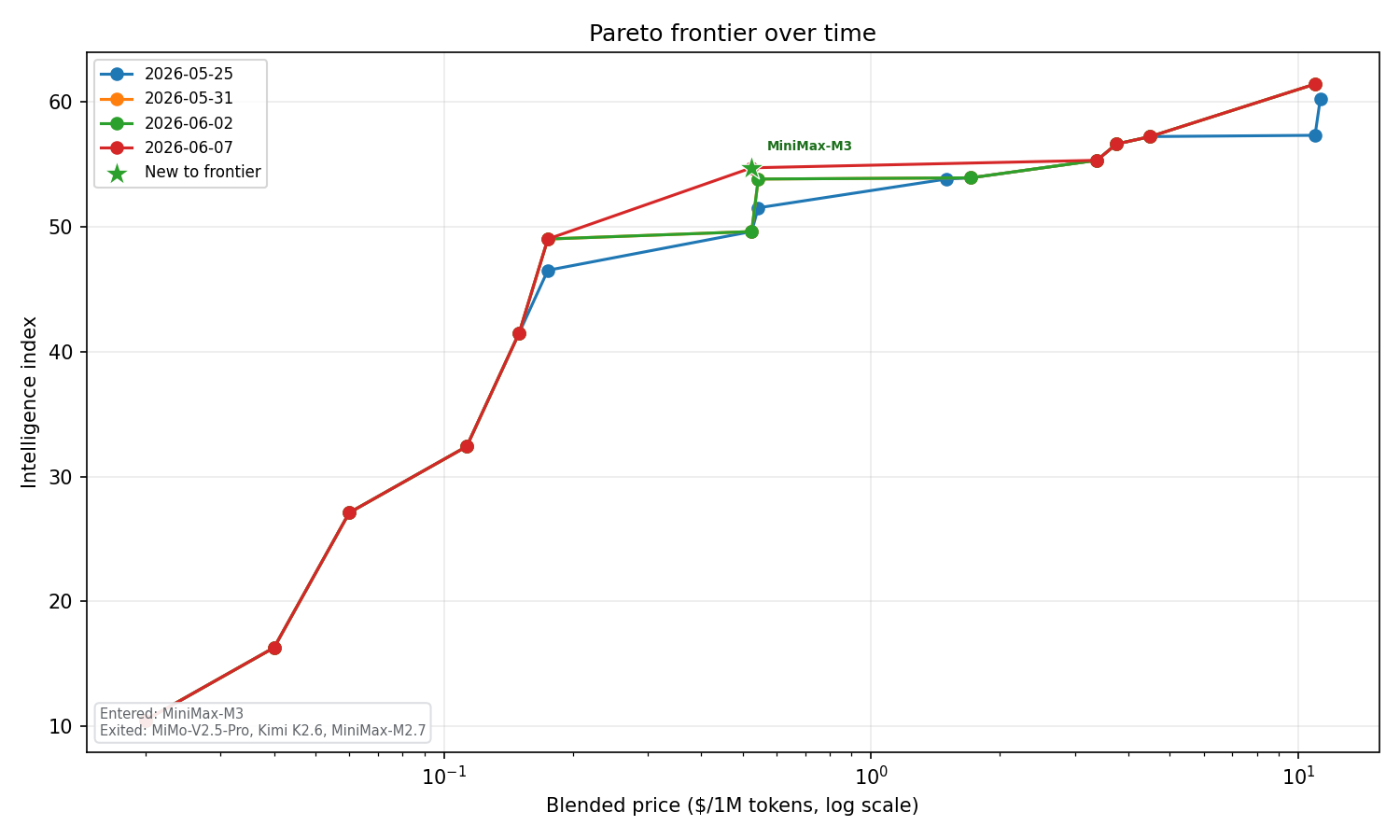
Across the four weekly snapshots banked so far, the frontier has both narrowed and gotten cheaper at the bottom: 15 models qualified on 2026-05-25, 11 do now, and the median frontier price fell from about $0.54 to $0.18 per million tokens. The ceiling moved too — Claude Opus 4.8 pushed the top frontier intelligence score from 60.2 to 61.4. Read together: the rational choice set is shrinking even as the cheap end of it gets dramatically cheaper.
Methodology & sourcing
Data comes from the Artificial Analysis free API (Intelligence Index v4, blended price at a 3:1 input:output ratio). "On the frontier" means Pareto-undominated on the intelligence-vs-price plane — no cheaper model matches its intelligence, and no smarter model costs less. This page reflects the snapshot dated 2026-06-07 and is refreshed roughly weekly. Numbers are a cross-section, not a benchmark of task-specific performance — see The Pareto Frontier Is the Model Market Map for the fuller argument behind this view.